Exploratory analysis is will cover basic visualisations and characterisations of the data as well as any initial transformations (e.g., library size) required before we move on to identifying differentially expressed genes.
What is exploratory analysis and why is it necessary?
Exploratory analysis is looking at the data. You are attempting to get a sense of what the data looks like, to notice outliers or issues (e.g., hey isn’t it weird that one of my wt samples groups with all the mutant samples, and one of the mut samples groups with the wt samples? I wonder what’s happening there?).
If your data set was a physical problem (like a squeaky wheel or a well wrapped present) you’d physically explore it (pick it up, is it heavy, do I shake it?). Exploratory analysis is the data science equivalent.
Exploratory analysis
Use the import data set or read.delim() function to import the file yeast_counts_all_chr, and name the object fcData. Also, load the dplyr library. We will look at some of the basic stats and features of our data object with View(), dim(), and names()
library(dplyr)
Attaching package: 'dplyr'
The following objects are masked from 'package:stats':
filter, lag
The following objects are masked from 'package:base':
intersect, setdiff, setequal, union
# If you are completing this workshop on the NeSI OpenOnDemand platform, run the code below to load the file. # fcData <- read.delim("~/RNA_seq/yeast_counts_all_chr.txt", comment.char="#")## I'm loading from my own local machine, so my filepath is different:fcData <-read.delim("~/Library/CloudStorage/OneDrive-UniversityofOtago/Documents/Training Coordinator 2022/GitHub/RNA-seq-data-analysis-workflow/data/yeast_counts_all_chr.txt", comment.char="#")View(fcData)fcData %>%head()
That already looks much better. Now, let’s split out the count data, removing the annotation (e.g., Chr, Start, End) columns and adding Geneid back into the object as the row names. Having the geneid as rownames is much easier than having that data as a column. Save a copy of this counts object for loading later.
This is a very basic, very ‘clean’ R object. We can see our sample names, gene names and counts easily. It is entirely possible to use this object for the rest of our analysis - and that’s what we will do today, for the sake of simplicity. This object is easy to interact with and is easy to mentally visualise and conceptualise.
However, it’s worth noting that many newer R packages and workflows will require (or at least strongly encourage) you to use a “summarised experiment object”. If a vector is a one-dimensional data storage object, and a matrix is a two-dimensional data storage object, you can think of a summarised experiment object as a three-dimensional way of storing data. In a summarised experiment object where you have the genes on the y axis and the samples on the x axis with counts as the observations, the z axis could be a second matrix storing different observations. Summarised experiment objects can stack multiple data types in this way and build up a complex (but tidy) array of data. Summarised experiment objects are powerful but can be harder to mentally conceptualise and require more complex code to interact with the data they store.
The summarised experiment object, image from the Carpentries Incubator Introduction to Data Analysis with R workshop.
Remove non-expressed genes (optional)
If you are working in a complex organism, many genes will not be expressed in all tissue types. It can be worth checking to see how many genes have zero (or e.g., < 5) counts and opting to remove these from your data object.
How many genes have counts of zero? How many genes have fewer than e.g., 5 counts?
Because our zeros are not a massive part of the data (i.e., here they are < 10% of the data), we will not remove them. However, they are worth noting because later we will consider logging our data, and zeros will cause an issue.
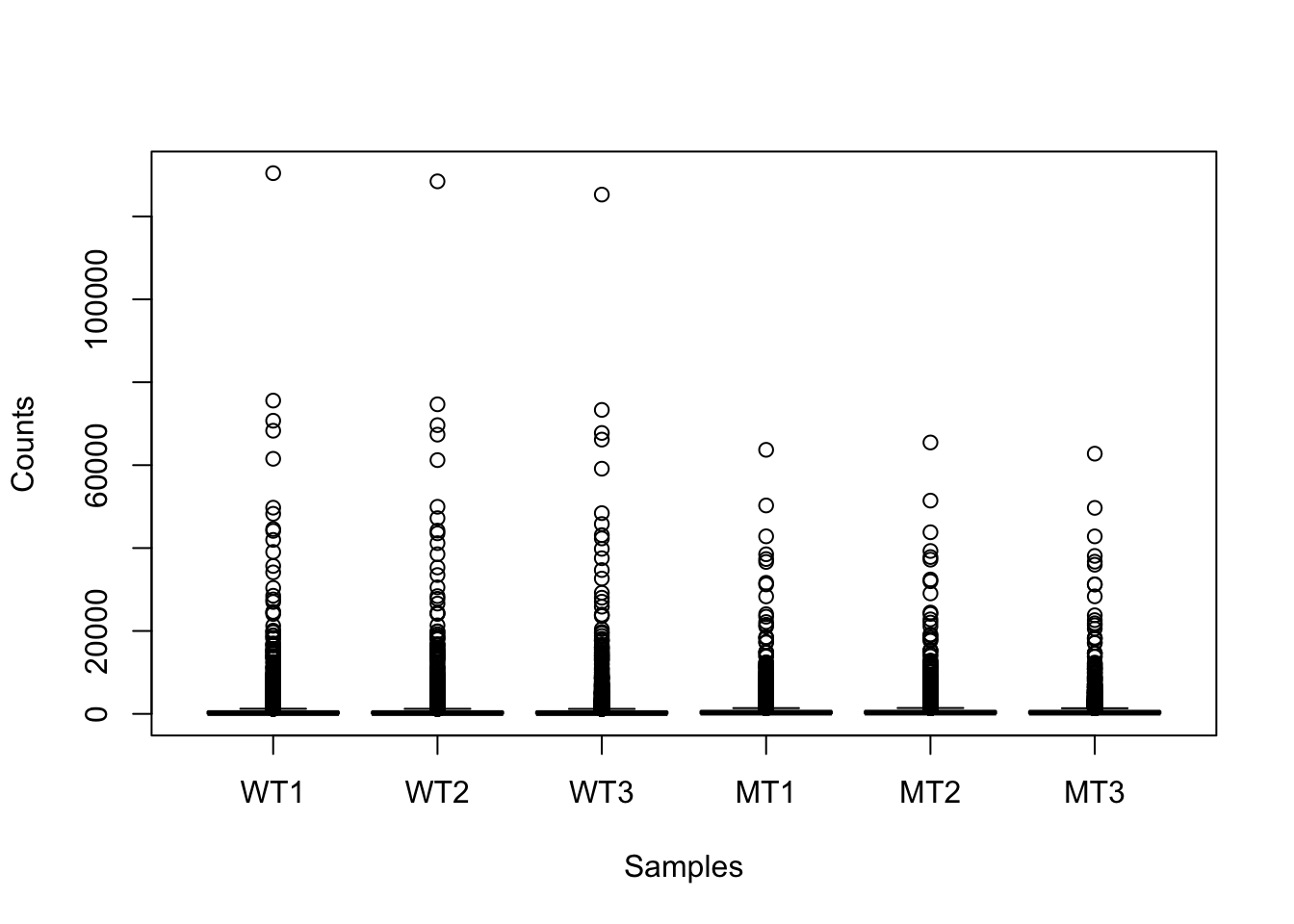
This figure indicates we should consider logging our data (for the purpose of visualisations).
Log transform the data, adding 0.5 to avoid log(0) errors.
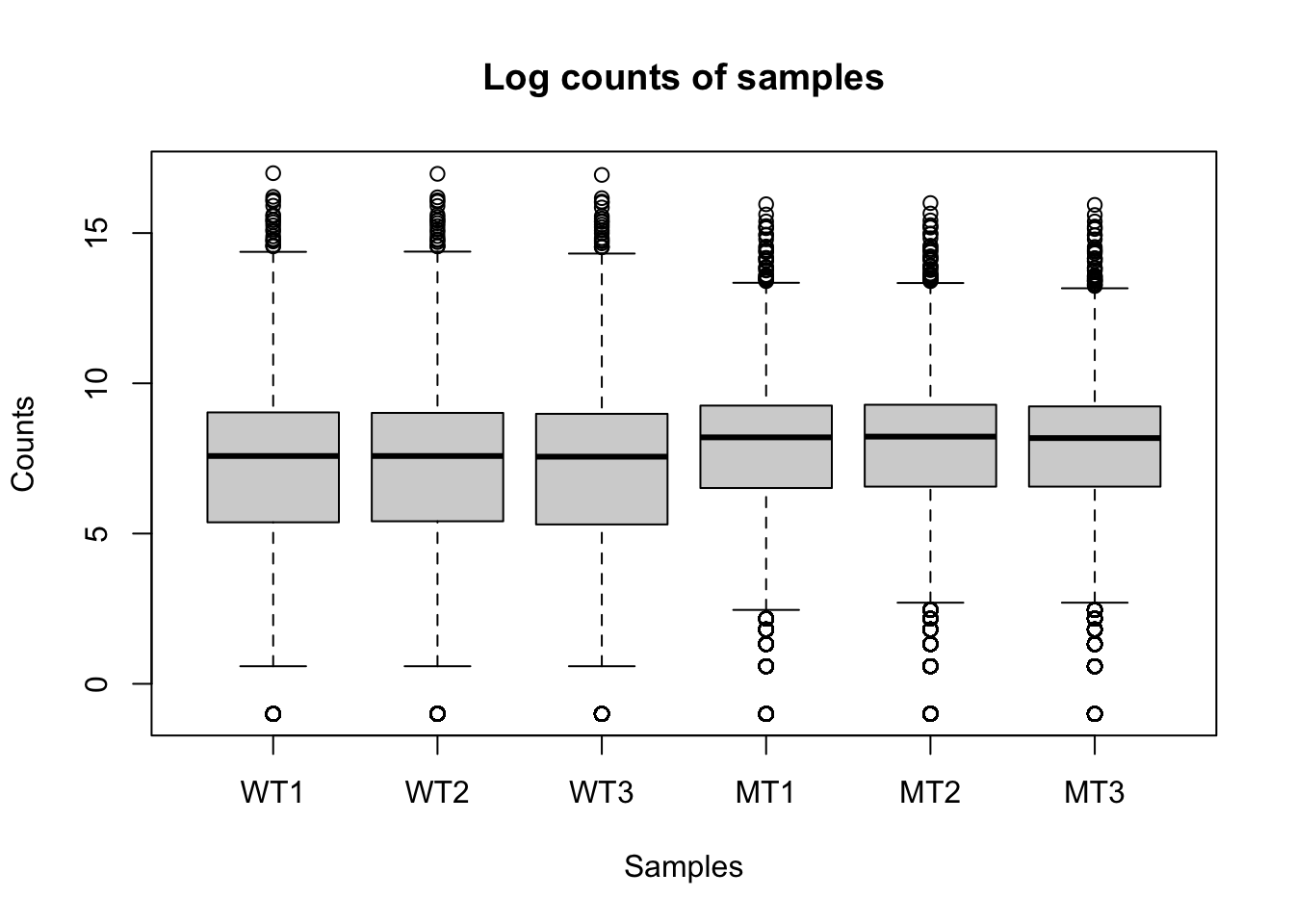
logCounts =log2(as.matrix(counts) +0.5)boxplot(as.matrix(logCounts) ~col(counts), ylab ="Counts", xlab ="Samples", names =colnames(counts), main ="Log counts of samples")
The log count boxplots reveal a difference between our wt and mutant samples. As a reminder, these two strains of yeast are very different and we would not normally expect this level of difference (although that might vary depending on your experiment).
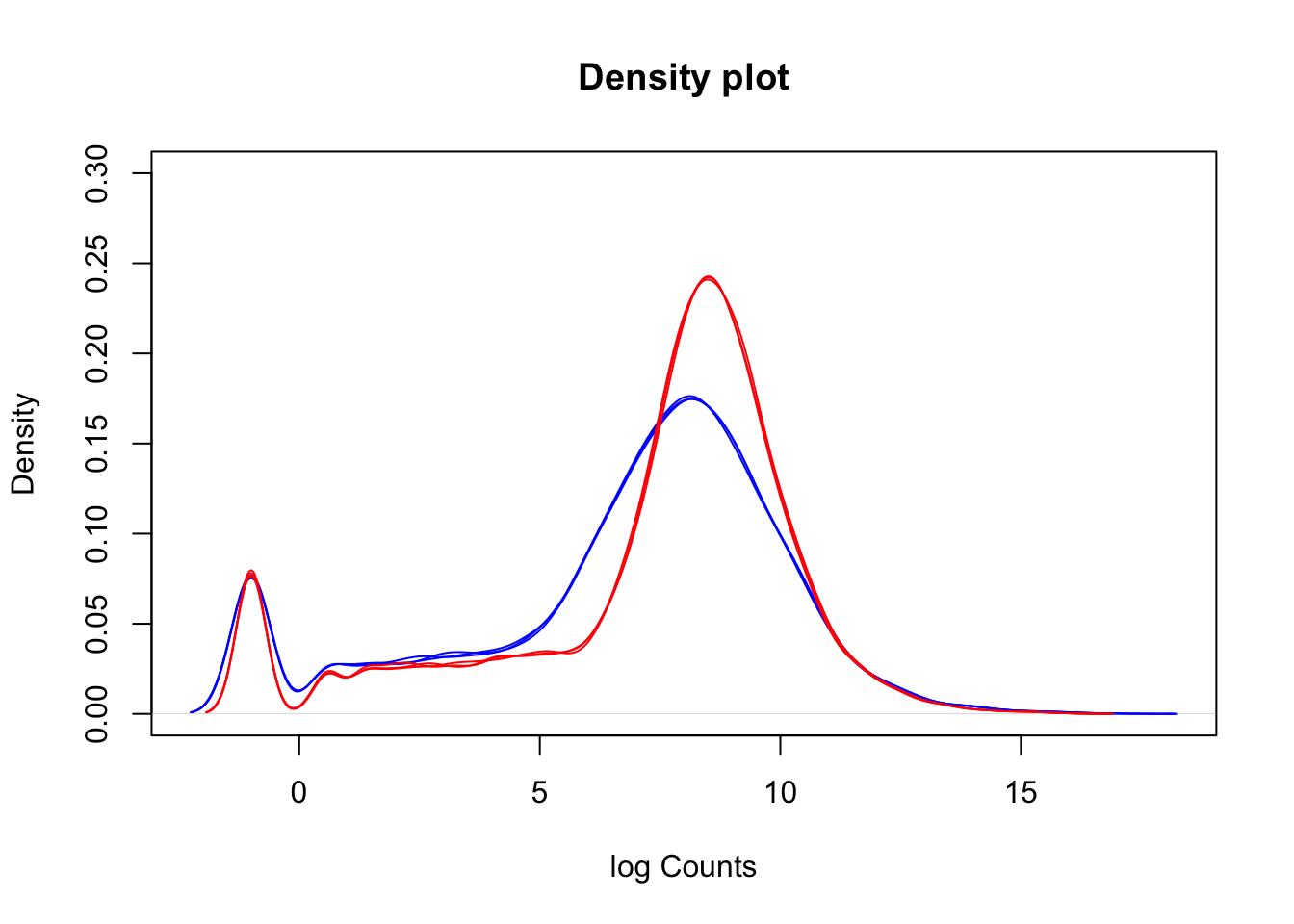
We can use density plots as another way to visualise differences between our two sample groups. First, create an object called lineColour which will colour our wt samples blue and our mutant samples red. Then create a density plot for the first sample, and use a loop to density lines for the remaining samples onto the plot.
A common question to ask at this point is, are the differences we can see between our two sample groups a true biological effect, or is this an experimental artifact? Often, we will not know the answer to this question. For now, it is enough to be aware of these differences and to keep them in mind moving forward.
Library size
Library size refers to the total number of reads for the entire sample. If two samples have vastly different library sizes, genes would look differentially expressed between samples e.g., if one library was twice as large as another, all genes would look to be upregulated in the larger library sample. Before we compare counts across samples we need to check whether the library sizes are approximately similar, and if they are not, make a correction to account for the size differences.
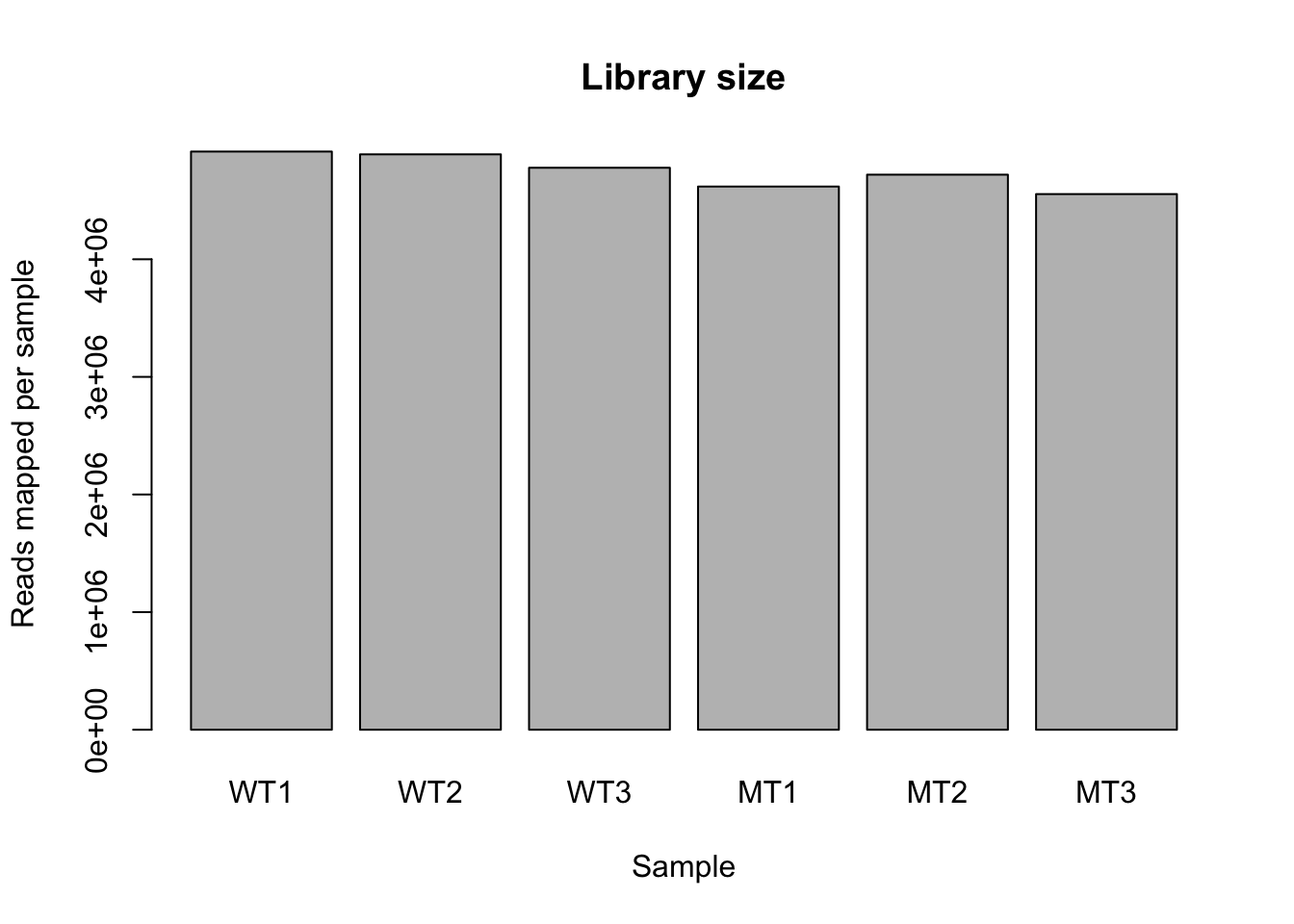
colSums(counts) %>%barplot(., ylab ="Reads mapped per sample", xlab ="Sample", main ="Library size")
Library sizes are approximately equal across the samples. They are slightly lower in the mutants compared to the wt, but the difference is low (i.e., mean ~ 4.6 million and 4.8 million reads in mutant and wt respectively).
If we needed to correct for library size, we would use a two-step method. In the first step we calculate a sample-specific value called a size factor. If we take the raw read counts and divide by the size factor for each sample, the resulting values would be similar for all samples. The way in which size factors are implemented will differ depending on the analysis method used. For some methods the size factor must be manually used to correct for library sizes. For other methods (e.g., DESeq2, which we will use shortly) automatically estimates size factors and implements them into the differential gene expression analysis workflow.
Heteroskedasticity
Heteroskedasticity is “heterogeneity of variance”. If the variance we observe is non-uniform across a range of values, we can describe the dataset as heteroskedastic. In RNA-seq, this means that variance depends on the mean expression of the gene. Wikipedia has a useful example:
“A classic example of heteroscedasticity is that of income versus expenditure on meals. A wealthy person may eat inexpensive food sometimes and expensive food at other times. A poor person will almost always eat inexpensive food. Therefore, people with higher incomes exhibit greater variability in expenditures on food.”
Exercise: Given the above example, do you expect genes with higher expression to have higher or lower variance than genes with low expression? That is, which will have higher variance - genes with high average expression or genes with low average expression?
This can be a surprisingly complex question to answer, and depends on how we think about variance. If a gene has a high mean expression (e.g., say 1000), then we can expect that the standard deviation will be a reasonably high number (e.g., let’s say 20). If a gene has low mean expression (e.g., 10), then the standard deviation will be small (e.g., 2). So, it is true to say that for genes with higher average expression, the standard deviation is greater.
However, we also need to think about magnitude of variance, which we can do using the numbers from our above imaginary examples. For the gene with a mean expression of 1000 and sd of 20, going from 1000 to 1020 is not a big change. For the gene with the low mean expression, going from 10 to 12 is a large change.
This write-up gives an in-depth explanation of heteroskedasticity and how we can think about it.
We will look more at heteroskedasticity when we begin to identify differentially expressed genes, but for now it is important to be aware of the concept.